[ICML2025] Reflection-Bench: Evaluating Epistemic Agency in Large Language Models
Abstract
The increasing deployment of large language models (LLMs) as autonomous agents necessitates rigorous evaluation of their fundamental agency capabilities in complex real-world environments. Drawing on cognitive psychology, we introduce Reflection-Bench, a novel benchmark that conceptualizes agent-environment interaction as an integrated reflection process encompassing seven interrelated cognitive dimensions: predictive processing, decision-making, perception, memory, counterfactual thinking, belief updating, and meta-reflection. Distinguished by its parameterized design and contamination-free nature, Reflection-Bench enables systematic assessment across varying difficulty levels while minimizing training data overlap. Our comprehensive evaluation of 15 current LLMs using three prompting strategies reveals a clear performance hierarchy and identifies critical limitations in current models. While leading LLMs demonstrate basic agency capabilities, they struggle with meta-reflection and cross-functional cognitive integration. These findings highlight the gap between current LLM capabilities and the requirements for reliable autonomous agents, suggesting directions for future development in strengthening core cognitive functions, improving cross-functional coordination, and enhancing adaptive processing mechanisms.
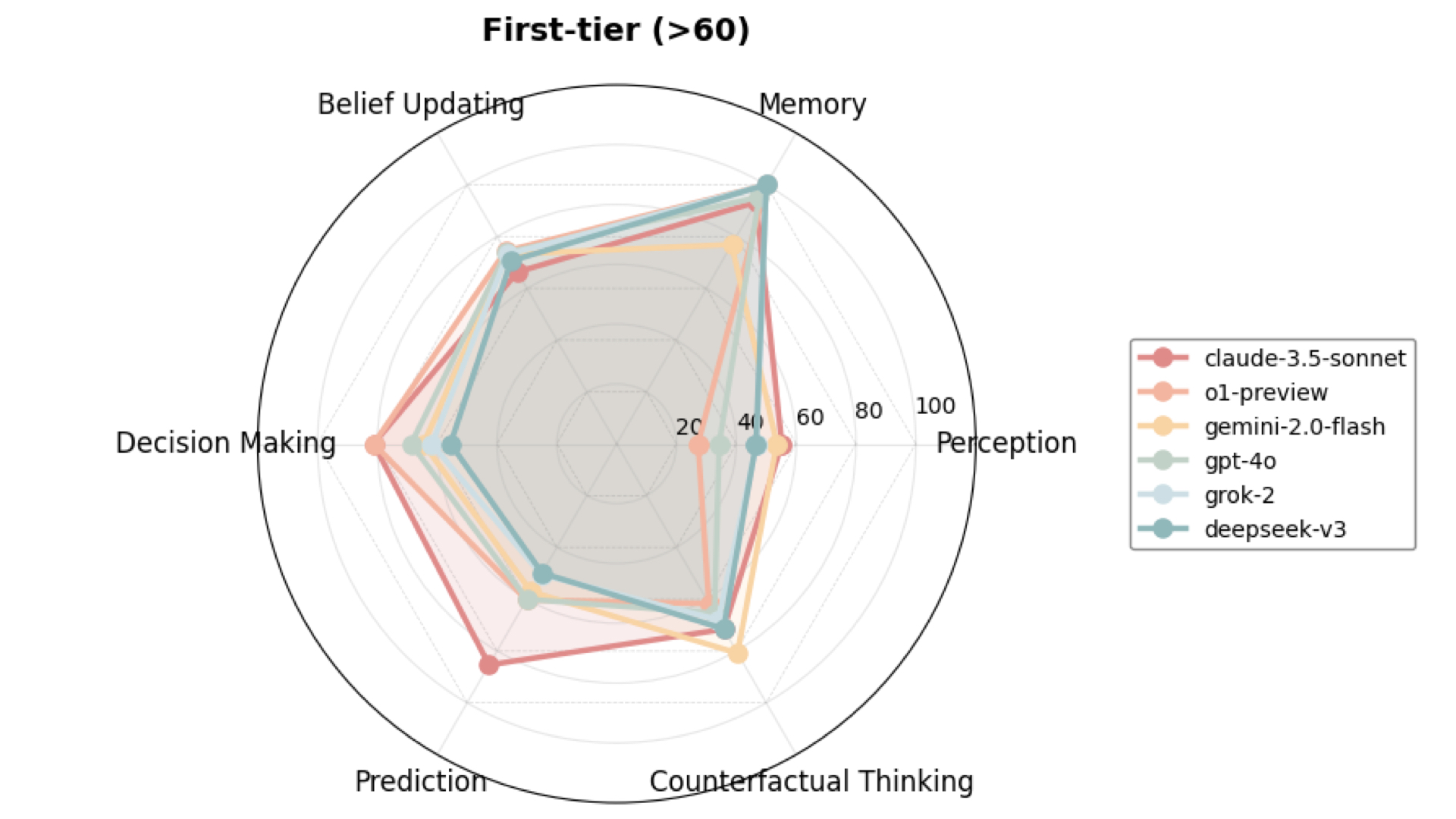
First-Tier
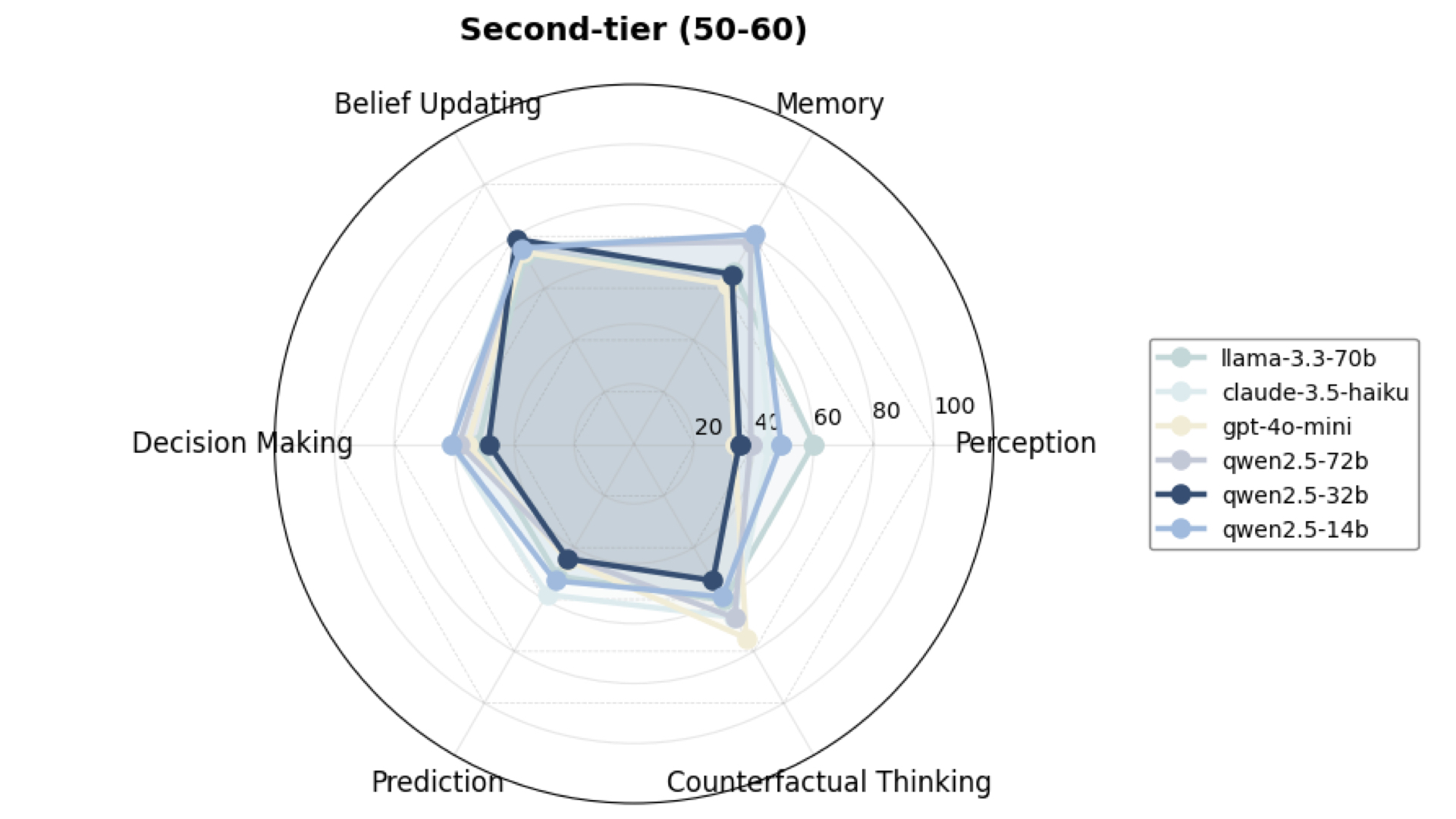
Second Tier
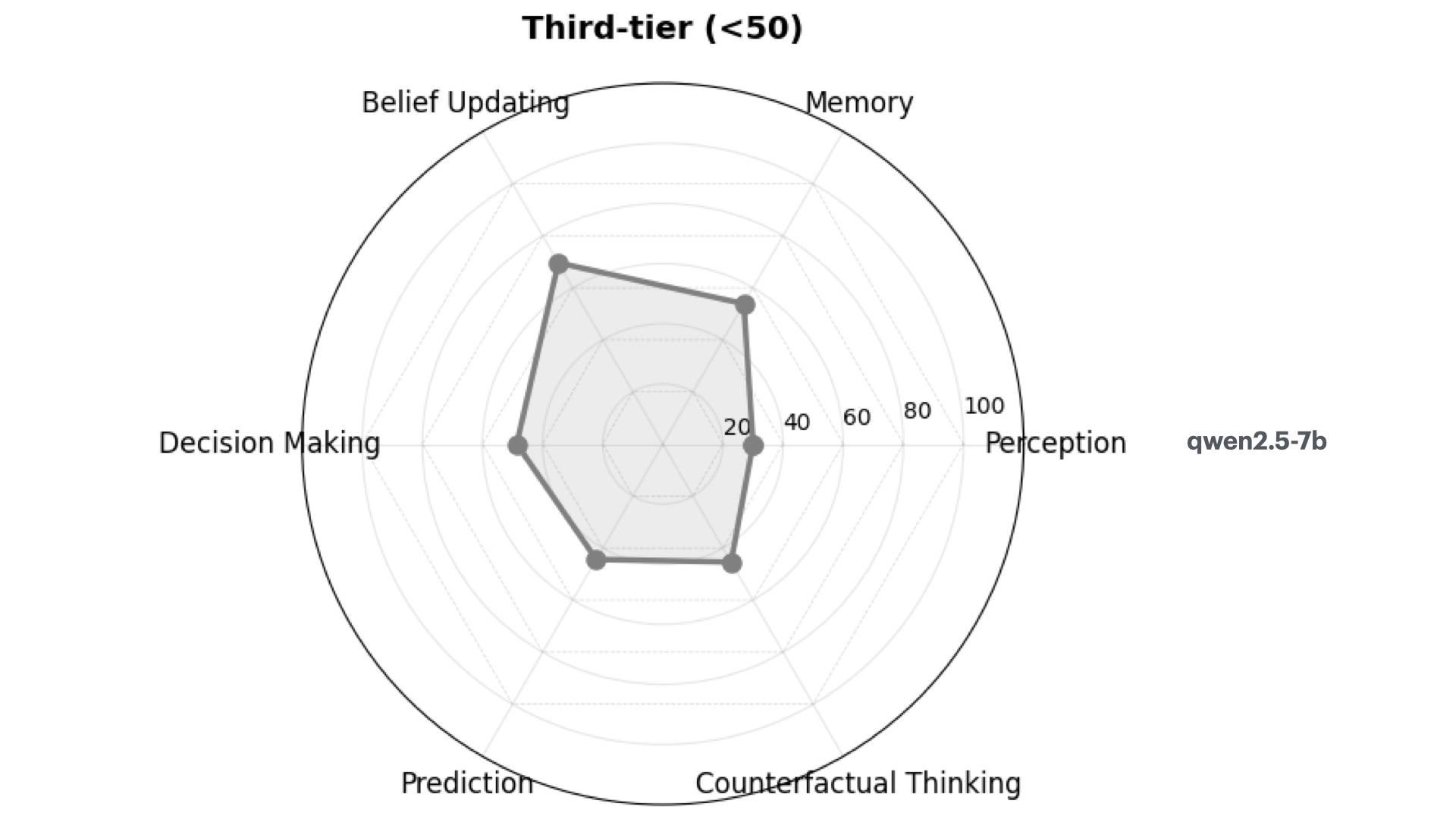
Third Tier
BibTeX
@misc{li2024reflectionbenchprobingaiintelligence,
title={Reflection-Bench: probing AI intelligence with reflection},
author={Lingyu Li and Yixu Wang and Haiquan Zhao and Shuqi Kong and Yan Teng and Chunbo Li and Yingchun Wang},
year={2024},
eprint={2410.16270},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2410.16270}}